Proj-01
Simple Video Cover Extractor for Bilibili
「简易 B 站视频封面提取器」
由于这是我们的第一节,仍然会杂一些比较基础的东西。(尽管这些东西大多都在补注里)
背景
想起我最开始学 Py 的时候,也是从 B 站下手的(逃)
我们在刷 B 站的时候,有可能经常会看到一些用某些「好书」来当作封面的视频。为了丰富我们的「知识库存」,我们势必要拿到封面去做以图搜源。 为此有些 B 站老哥在视频评论区向鸽子 UP 主苦苦求了几万年(大雾)
啊肯定有些机智的朋友知道些别的途径 ,像用那些在线工具啊、用「一个■函」APP 啊、在网页端按 Ctrl+U 然后慢慢找啊之类的。 不过我们这次要来尝试自己写一写用来做这个的程序。
准备工作
由于这是我们第一次正式开始搓 Python 项目,我们需要养成一些良好的习惯。 不要像我这样埋头弄三年结果 PEP8 都不知道
在上一节我们已经装好了 Python。由于这次我们会用到第三方库,所以要配置虚拟环境。
你也不想污染在上一节中刚弄好的全局环境罢()
照例创建一个项目文件夹,然后使用 VSCode 打开,信任此文件夹的作者。
创建虚拟环境
接下来我们创建虚拟环境(通过 VSCode 和 Venv)。
按 Ctrl+Shift+P 组合键呼出 VSCode 顶部的运行指令菜单,找到 Python: Create Environment...

环境类型选择 Venv

选择合适的解释器
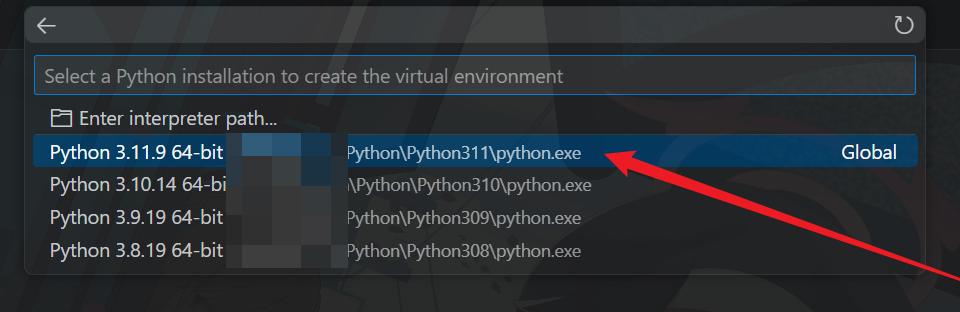
等待创建完成后,在 VSCode 窗口右下角确认选择的虚拟环境是否正确
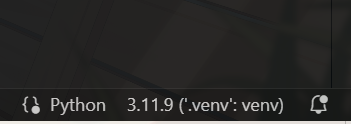
关于手动创建,参见补注。
注意
有时明明右下角已经显示选中了虚拟环境,但是用 pip 一装包就发现装到全局环境去了。要确认是否已经真正进入虚拟环境,可以参考补注中的方法。
至此,虚拟环境创建完成。
安装第三方库
由于 Python 的标准库中的网络请求库使用体验稍显繁琐,所以这里选择第三方库 requests 作为替代。
在 VSCode 中打开终端
按
Ctrl+Shift+`启动一个新的终端,或者按Ctrl+`切换到已打开的终端。
安装网络请求库 requests
如果使用了更高级的包管理工具如 PDM,做相应的调整即可。毕竟要装的包都是一样的。
pip install requests types-requests安装
types-requests是为了支持mypy静态检查
安装 XML 解析库 lxml ,用于解析网页
pip install lxml types-lxml等待完成后,将已安装的包固定为 requirements.txt
如果是 PDM,依赖会在添加时自动写入到
pdm.lock和pyproject.toml
pip freeze > ./requirements.txt这样一来下次安装时就可以使用 pip 的 -r 参数一键搞定了。
开始喵
寻找途径
首先我们要明确我们的目标,是要获取到 B 站的某个视频的封面是吧。想想我们有哪些方法。总之找一个视频做样本罢。
刷刷首页 —— 袜这个封面好卡瓦,就它了! (草
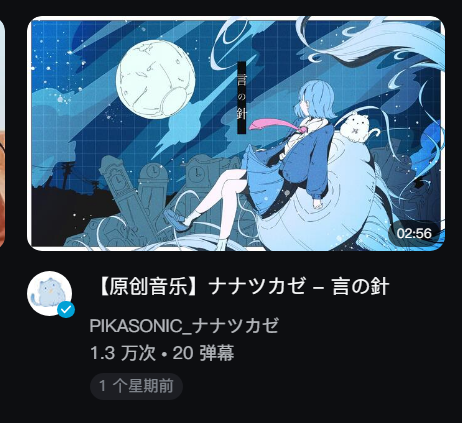
获得它的网址: https://www.bilibili.com/video/BV1iW421R71g
网址后面可能会跟上一串乱七八糟的东西(用来追踪用户行为的特征字段),但是熟悉 B 站的朋友们都知道,定位一个视频只需要 AV 号(记作
aid或avid)或者 BV 号(记作bvid)就行了。
得到它的关键数据 BV1iW421R71g (bvid),保留备用。
进入视频详情页,将光标悬停在分享按钮上,右击弹出的分享框中的封面,可得到封面网址。
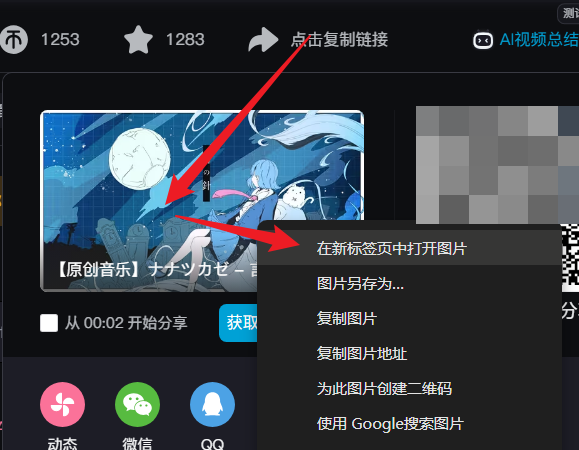
得到了这样一个 URL: https://i0.hdslb.com/bfs/archive/2ff337f507754e0d172298d3e9b815413b4a63b7.jpg@518w_290h_1c_!web-video-share-cover.avif
它看上去很小,并且保存下来也是 .avif 文件,不便查看。
但是细心观察不难看出,整个 URL 由图片本体和调整参数组成,去除 @ 符及其往后的内容再打开便是原始图像了。
这样做一般是为了减小带宽压力,将图片在服务端压缩后再提供给客户端。
现在我们拿到了封面 URL,可以反过来用 URL 来定位它在网页中的位置了。
按下 F12 打开开发者选项,找到 元素 选项卡, Ctrl+F 打开查找选项再一粘贴搜索,欸怎么没有呢
将搜索范围缩小到后半段的图片哈希值,成功找到元素。
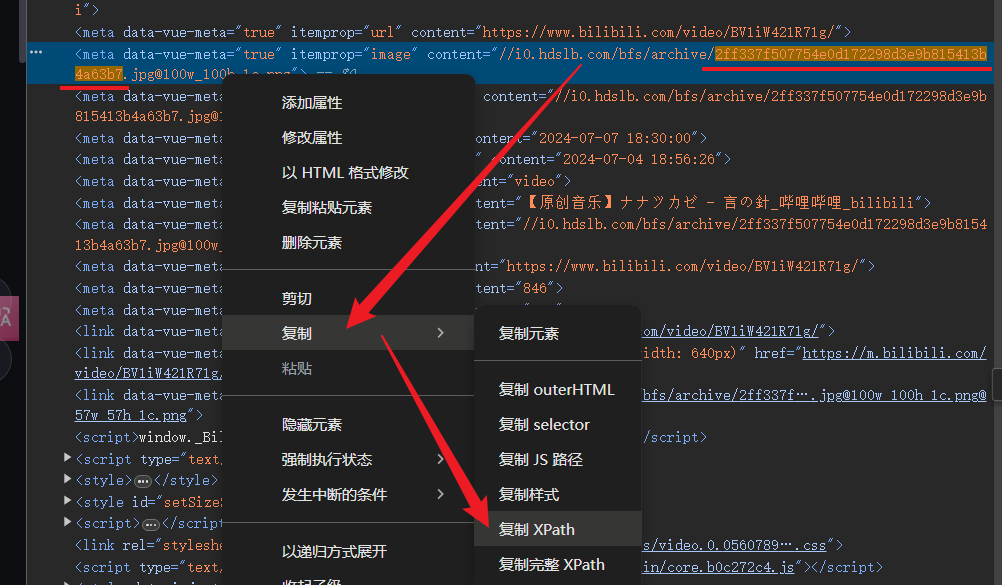
之后要通过 lxml 库解析网页,记下这个元素的 XPath 备用。
注意网页的结构具有时效性,因为你不知道它多久会再改版。改版导致的页面结构的改变可能会使你得到的
XPath之类的记录元素位置的信息失效。因此更理想的方法一般是找到网页的 API,直接通过请求 API 拿到信息,API 的有效时间通常会更长一些。不过我们暂时先留到以后再说,本节我们先做这个。
当然也有别的元素定位方法和库可以用,只是这里使用了
lxml和 XPath 而已。
写
新建一个 py 文件,就叫 main.py 好了。
我们将要实现一个函数,这个函数接收视频的 URL,返回视频封面的 URL。大概长这个样子。
def get_video_cover(url: str) -> str:
pass基础语法参见补注或者另一组写的文档,或者搜索引擎启动
实践流程见 notebook
优化
我们已经在 notebook 编写了一遍最简单的代码。接下来我们将它封装为函数。
将主体部分缩进一级,将预设的 URL 改成传入参数,将打印封面 URL 改成返回封面 URL,移除多余的打印语句。将作为常量的 headers 和 xpath 改写为全大写,放在函数外面。添加 main 函数。
若当前模块中的
__name__变量内容为"__main__",则说明当前模块是被直接运行的。否则此变量的内容为当前模块的名字。这使得模块既可以作为独立脚本执行,又可以作为模块被复用。
完整代码见 source
结束了喵
但是我们的程序还很「脆弱」,还有一些地方值得改进,尝试自己解决吧!
程序没有容错机制,这意味着如果程序遇到网络不通畅等异常情况时,会直接因为出错而退出。此外
lxml在找不到XPath指向的元素时会返回空值,会导致后续程序出错。尝试加上容错机制。Hint:
try ... except ...和 额外的返回值检查。程序不会检查用户的输入,这意味着它会尝试请求任何用户输入的东西,甚至不管它是不是 URL。尝试改进这一点。
Hint: 尝试提取输入中的 AV 号或 BV 号,拼接成网页 URL 后再拿去做请求。
程序只是打印出了封面 URL,却没有将它自动下载下来。尝试为它加上这个功能。
Hint:
open()(续)难道下载的文件的名字要叫那一长串哈希字符串吗?尝试获取视频的标题,然后将它当作下载的封面的文件名。
以及,去尝试通过这种方式获取更多网页中的信息吧!